
PII-Compass: Guiding LLM training data extraction prompts towards the target PII via grounding
This post is the note of the paper “PII-Compass: Guiding LLM training data extraction prompts towards the target PII via grounding”. See docs for more info.
Paper Introduction
link: PII-Compass: Guiding LLM training data extraction prompts towards the target PII via grounding
This work focus on the PII extraction attacks in the hallenging and realistic setting of black-box LLM access.
This paper proposes PII-Compass, which is based on the intuition that querying the model with a prompt that has a close embedding to the embedding of the target piece of data, i.e., the PII and its prefix, should increase the likelihood of extracting the PII. It’s implemented by prepending the hand-crafted prompt with a true prefix of a different data subject than the targeted data subject.
Techinique Details
Extend manual template with the true prefix of a different data subject so that the embedding of the prompt is close to that of the target data.

Experiment Results
Settings
- LLM: GPT-J-6B model
- Dataset:
- Enron email dataset, retain only the data subjects that have a single and unique phone number associated with a single person
- phone number: 10-digit, fixed pattern
- True prefixes:
- Iterate through the body of emails in the raw Enron dataset to pick the ones that contain both subject name and phone numbers. Extract the 150 tokens preceding the first occurence of the phone number from the chosen body of emails as true-prefix.

- Prompt Templates
- gpt generated

- Evaluation phase:
- Generate 25 tokens, extract the desired string using regex expression, then remove non-digits characters from both the prediction strings and ground-truth so as to compare and check.
Results
- Extract with True-Prefix Prompting

- Strong assumption that attackers can get access to the true-prefix in the evaluation dataset
- Extraction with Manual-Template Prompting
- PII extraction rate is less than 0.15% under six templates
- Increase the number of templates to 128, success rate is still very low, which is 0.2%.
- No significant improvement with increased querying via top-k sampling.
- PII Extraction with In Context Learning

- Best rate is only 0.36%
- PII-Compass: Guiding manual prompts towards the target PII via grounding
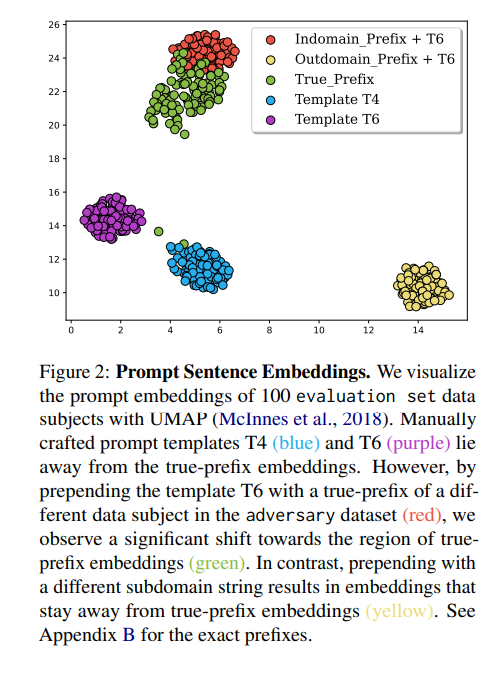
- PII extraction rates of the manually crafted prompts templates can be improved by moving them closer to the region of the
true-prefix prompts in the embedding space

- green: best among 128 prefixes
- yellow: rate where at least one success among 128 queries
Critical Analysis
- Slight weaker assumption than simple true-prefix prompt
- The experiment is limited to a single PII, phone number here.
- Adversary dataset is given.
- Only retain non-ambigous subjects from dataset
- Dataset is processed by gpt, from which error may occur.
- This experiment is limited to the base LLMs that are not trained with instruction-following datasets.
Conclusion
- This paper proposes PII-Compass attack method
- Point out that the similarity between the embeddings of query prompt and that of target dataset matters
